Hoog-Niveau Concepten
Deze documentatie is automatisch vertaald en kan fouten bevatten. Aarzel niet om een Pull Request te openen om wijzigingen voor te stellen.
LlamaIndex.TS helpt je bij het bouwen van LLM-aangedreven applicaties (bijv. Q&A, chatbot) over aangepaste gegevens.
In deze gids met hoog-niveau concepten leer je:
- hoe een LLM vragen kan beantwoorden met behulp van je eigen gegevens.
- belangrijke concepten en modules in LlamaIndex.TS voor het samenstellen van je eigen query-pijplijn.
Vragen beantwoorden over je gegevens
LlamaIndex gebruikt een tweestapsmethode bij het gebruik van een LLM met je gegevens:
- indexeringsfase: het voorbereiden van een kennisbank, en
- queryfase: het ophalen van relevante context uit de kennisbank om de LLM te helpen bij het beantwoorden van een vraag.
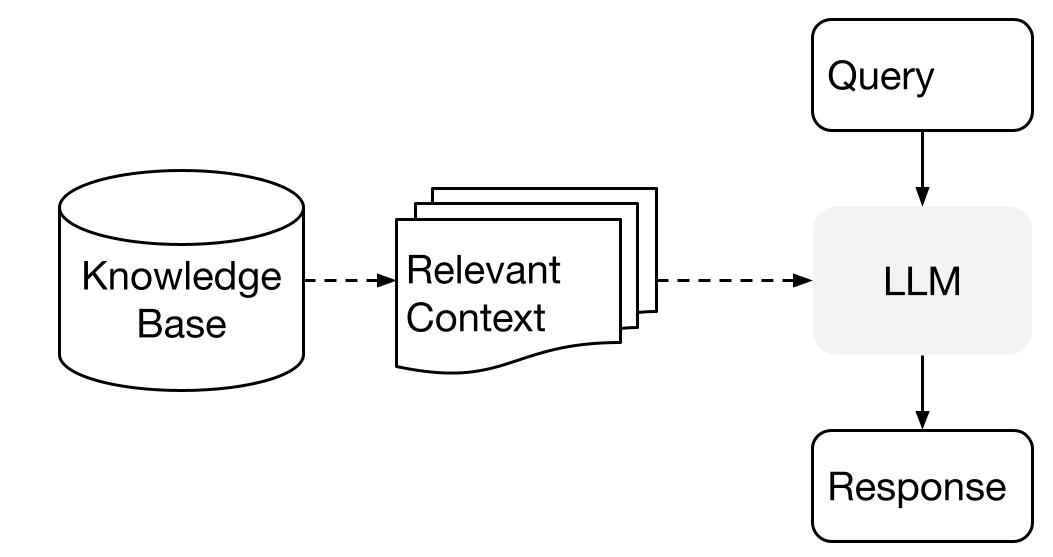
Dit proces staat ook bekend als Retrieval Augmented Generation (RAG).
LlamaIndex.TS biedt de essentiële toolkit om beide stappen super eenvoudig te maken.
Laten we elke fase in detail bekijken.
Indexeringsfase
LlamaIndex.TS helpt je bij het voorbereiden van de kennisbank met een reeks gegevensconnectoren en indexen.

Gegevensladers:
Een gegevensconnector (bijv. Reader) neemt gegevens op uit verschillende gegevensbronnen en gegevensindelingen in een eenvoudige Document-representatie (tekst en eenvoudige metadata).
Documenten / Nodes: Een Document is een generieke container rondom elke gegevensbron - bijvoorbeeld een PDF, een API-uitvoer of opgehaalde gegevens uit een database. Een Node is de atomaire eenheid van gegevens in LlamaIndex en vertegenwoordigt een "chunk" van een bron-Document. Het is een rijke representatie die metadata en relaties (naar andere nodes) bevat om nauwkeurige en expressieve ophaalbewerkingen mogelijk te maken.
Gegevensindexen: Nadat je je gegevens hebt opgenomen, helpt LlamaIndex je bij het indexeren van gegevens in een formaat dat eenvoudig op te halen is.
Onder de motorkap analyseert LlamaIndex de ruwe documenten in tussenliggende representaties, berekent vector-embeddings en slaat je gegevens op in het geheugen of op schijf.
"
Queryfase
In de queryfase haalt de query-pijplijn de meest relevante context op op basis van een gebruikersquery, en geeft dit door aan de LLM (samen met de query) om een antwoord te genereren.
Dit geeft de LLM actuele kennis die niet in zijn oorspronkelijke trainingsgegevens staat, (ook het verminderen van hallucinatie).
De belangrijkste uitdaging in de queryfase is het ophalen, orchestreren en redeneren over (mogelijk vele) kennisbanken.
LlamaIndex biedt samenstelbare modules die je helpen bij het bouwen en integreren van RAG-pijplijnen voor Q&A (query-engine), chatbot (chat-engine), of als onderdeel van een agent.
Deze bouwstenen kunnen worden aangepast om voorkeuren voor rangschikking weer te geven, en kunnen worden samengesteld om op een gestructureerde manier redeneringen uit te voeren over meerdere kennisbanken.
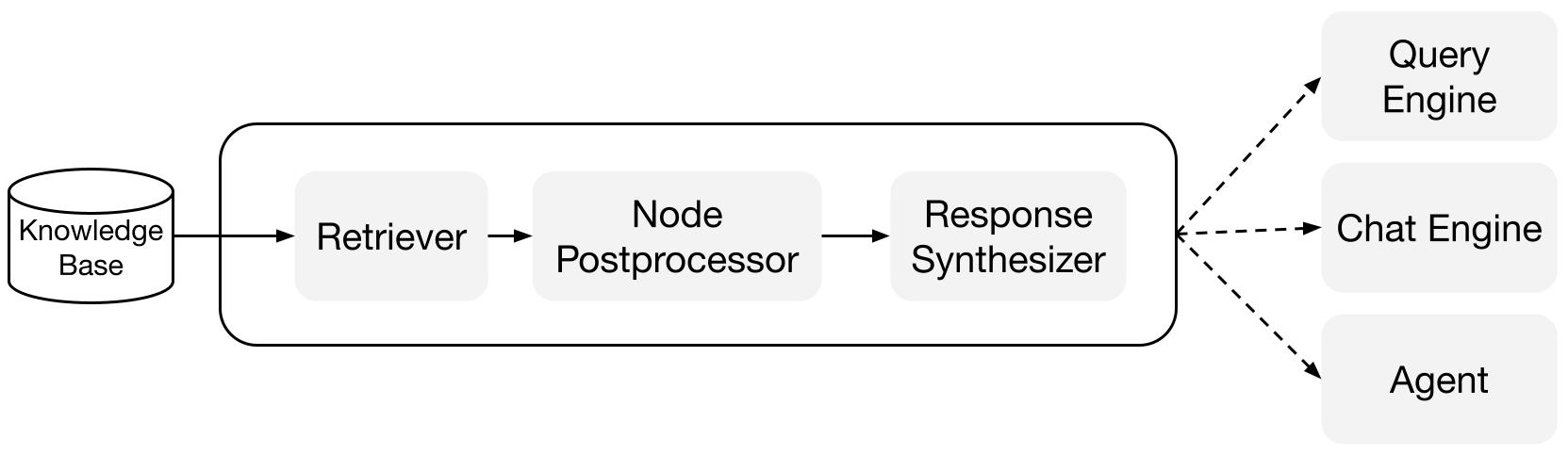
Bouwstenen
Retrievers: Een retriever bepaalt hoe relevante context efficiënt uit een kennisbank (d.w.z. index) kan worden opgehaald wanneer een query wordt gegeven. De specifieke ophaallogica verschilt per index, waarbij de meest populaire dichte ophaallogica is tegen een vectorindex.
Response Synthesizers: Een response synthesizer genereert een antwoord vanuit een LLM, met behulp van een gebruikersquery en een gegeven set opgehaalde tekstfragmenten.
"
Pijplijnen
Query-engines: Een query-engine is een end-to-end pijplijn waarmee je vragen kunt stellen over je gegevens. Het neemt een natuurlijke taalquery in en geeft een antwoord terug, samen met de opgehaalde referentiecontext die aan de LLM is doorgegeven.
Chat-engines: Een chat-engine is een end-to-end pijplijn voor het voeren van een gesprek met je gegevens (meerdere heen-en-weer in plaats van een enkele vraag en antwoord).
"